Faithfulness
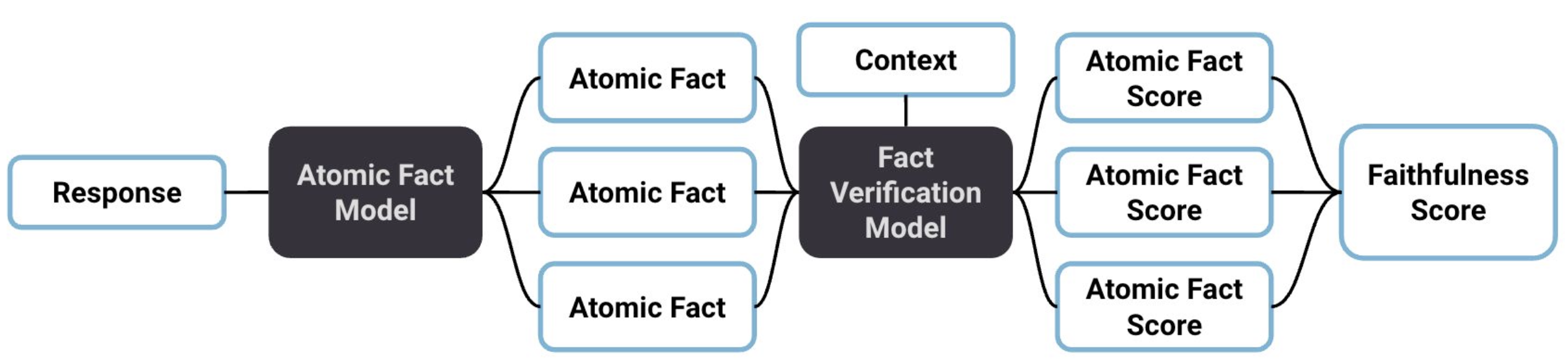
The Faithfulness metric judges whether the response is supported by the context. The response is split into individual, ‘atomic’ claims that contain only a single piece of information. Each of these claims is then verified with respect to the context, and the scores of these verifications are aggregated into a single Faithfulness score.
In addition to the label and score of each statement, the 'span' of the response that the statement is obtained from is provided. This range is inclusive and zero-indexed.
FAQs
What is the difference between 'intrinsic' and 'extrinsic' hallucinations?
Both intrinsic and extrinsic hallucinations are statements which are unsupported by the context.
An Intrinsic hallucinations is a statement which contradicts the context. For example:
- Context: "Shay Given played for Newcastle United and Manchester City."
- Statement: "Shay Given never played for Manchester City."
An Extrinsic hallucination cannot be verified using the context alone. Even if a statement is 'common-knowledge', it will still be labelled as an extrinsic hallucination unless it is explicitly supported in the context. An example may be:
- Context: "Shay Given played for Newcastle United and Manchester City."
- Statement: "Shay Given was a goalkeeper."
How do I know if a response is good?
The Faithfulness metric returns a number of 'statements', each of which has been verified as "Safe", "Intrinsic Hallucination" or "Extrinsic Hallucination". If any of the statements are labelled as "Intrinsic Hallucination" or "Extrinsic Hallucination", it cannot be verified with respect to the context and as such, the response may be unsafe.
The response looks good but the Faithfulness score is low - why could this be?
There are many reasons the Faithfulness score may seem confusing at first glance. A few of the common cases we've come across are given here:
- Verification is very strict: The verification model is designed to only mark a statement as safe if it is clearly supported in the context. Even if a statement is 'common knowledge', we don't mark it as safe this is so that we don't rely on the model's 'parametric knowledge', which can often be the causes of hallucinations in the first place. Additionally, hallucinations are sometimes given if the statement is inferred from the context. This is for a similar reason as 'common knowledge' statements - to avoid relying on a model's independent reasoning capabilities, which often hallucinate themselves.
- "I don't have enough information to answer that question..." - Poor context retrieval: Occasionally, an LLM is asked a question that can definitely be answered using the source documents, but it responds with something like: "I'm sorry, the provided context does not provide the information to...". Even though the document contains the necessary information, the RAG pipeline may have failed to identify the best context chunks, so the LLM doesn't receive anything useful. The Faithfulness metric is designed to give a low score in these cases. Some models continue the response by listing some of the context that it was provided, which results in a high Faithfulness score. It is for this case that it is often useful to check the Context Relevancy score before Faithfulness. If the Context Relevancy score is low, the provided chunks may be insufficient, so the answer from the LLM may not be useful and the faithfulness score may be unintuitive.
How do Faithfulness and Summarization differ?
Both metrics judge whether a response is supported by the provided context, but the difference lies in how this is achieved. Faithfulness verifies the response at the 'statement level', and thus is very fine-grained. In contrast, Summarization works at the 'sentence level', which is less fine-grained, but in exchange, it is faster.